

A passport encodes its holder's identity twice. The Visual Inspection Zone (VIZ) is the biographic page you hand to a border agent. It contains name, nationality, date of birth, and expiry in human-readable form. Below it, the Machine Readable Zone (MRZ) encodes the same data in a standardized format with arithmetic checksum fields built in. Every character group in the MRZ has a corresponding check digit calculated from a weighted modulo-10 algorithm.
Most passport OCR implementations extract both zones and stop there. Characters come out, get routed to a database, and the system reports success because text was extracted, without checking whether the MRZ checksums validate or comparing the VIZ name against its MRZ encoding.
That gap, between extracting characters and verifying structural integrity, is where passport OCR breaks down in production workflows.
The MRZ Is a Checksum-Validated Identity Record, Not Just Two Lines of Text
ICAO Document 9303, the UN standard governing machine-readable travel documents, specifies exact field positions, character encoding rules, and a checksum algorithm for every passport issued globally. The TD3 format used by standard international passports has two 44-character lines:
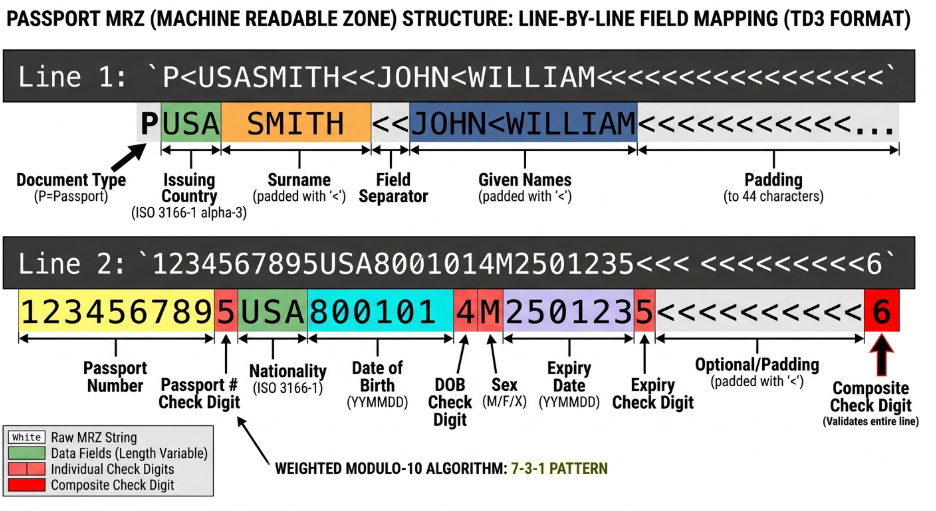
Line 2 holds passport number, nationality, date of birth, sex, expiry date, optional data, and a composite check digit that validates the full line. Each field is followed by a check digit computed by weighting its characters with the repeating pattern 7-3-1, summing the products, and taking the result modulo 10.
If the extracted passport number doesn't produce the correct check digit, the extracted value is wrong, either corrupted during capture or intentionally altered. Standard OCR extracts the characters. It has no awareness that the checksum exists.
The composite check digit in line 2 validates the passport number, date of birth, expiry, and optional data fields together. A document with a failed composite check may have been tampered with. That's a different category of problem from an OCR error, and treating it identically is what makes checksum-unaware extraction a liability in identity workflows.
| Standard OCR | Validated MRZ Parsing | |
|---|---|---|
| Character extraction | ✓ | ✓ |
| Field boundary enforcement | X | ✓ (fixed positions per ICAO 9303) |
| Per-field check digit validation | X | ✓ |
| Composite checksum validation | X | ✓ |
| VIZ-MRZ field cross-check | X | ✓ |
| Tamper signal detection | X | ✓ (via checksum mismatch) |
Document processing pipelines that treat MRZ output as unstructured text inherit all the failure modes of traditional OCR while discarding the structural safeguards the format was designed to provide.
What the Visual Inspection Zone Contains
The VIZ contains the holder's photo, printed name, nationality, date of birth, expiry date, issuing authority, and signature. These are the same data fields encoded in the MRZ, rendered in human-readable typeface for visual inspection.
Passport images capture the full biographic page, and the VIZ is where multiple languages and non-Latin scripts appear. An Arabic, Chinese, or Cyrillic name appears here in its native script. OCR pipelines without explicit script detection route these to models trained on Latin characters, producing garbled output or dropping the field entirely.
The VIZ is also where hologram placement, lighting angle, and laminate condition have the most impact on OCR accuracy. Security holograms are embedded in the biographic page overlay to deter document reproduction. Under non-ideal capture conditions, angled smartphone photos or fluorescent overhead lighting, holograms scatter light and create localized recognition failures on adjacent text fields. The MRZ, printed below the hologram region, is less susceptible to this. The VIZ sits directly in the interference zone.
Why Cross-Zone Validation Is the Gap Most Implementations Skip
Digitally altered passports typically show a discrepancy between VIZ and MRZ fields. A photo may be swapped while the VIZ name stays original. A VIZ expiry date may be modified while the MRZ expiry, structurally harder to alter convincingly, holds at the original value. A system that extracts both zones independently without comparing them won't catch this.
Cross-zone validation also enables recovery on damaged captures. A passport with the VIZ name field obscured by hologram glare still has a readable MRZ name encoding. An extraction system that treats each zone in isolation reports a failed extraction and returns an empty field. A cross-validating system uses the MRZ value when the VIZ is unreadable, flags the discrepancy for review, and returns a usable output.
Passport data extraction that reports high accuracy on clean test images often degrades on production passports precisely because VIZ-MRZ reconciliation was never part of the architecture.
The Failure Modes That Break Passport OCR Before You Get to the MRZ
The test documents OCR vendors use to demonstrate accuracy and the passports that show up in real deployment workflows look very different. You find this out fast.
Most production passport pipelines encounter at least some of the following regularly.
Hologram interference. Security holograms scatter light unpredictably under photography. Standard OCR pipelines trained on flat, evenly lit printed text have no compensation mechanism. OCR accuracy on adjacent VIZ fields drops on real-world passport images even when the image appears clear to a human reviewer. This is one of the most consistent gaps between benchmark performance and production performance in passport data extraction.
Non-Latin scripts. Passports from dozens of countries carry names containing Arabic, CJK, or Cyrillic characters in the VIZ. Without explicit script detection, these get routed to a Latin character recognition model. The output is garbled or dropped. The failure is silent. The system reports an extraction, but the value is wrong. Multilingual OCR that handles this correctly requires active script identification before model routing, not just a multilingual training dataset.
Travel stamps over printed fields. Customs and immigration offices stamp the biographic page, not just the visa pages. A stamp over the expiry date or nationality field partially hides the printed text. Standard OCR either misreads the combined pixels or skips the field without flagging the gap downstream.
Mobile capture quality. Hotel check-in workflows and digital onboarding apps depend on consumer smartphone captures under variable lighting, at angles, with lens distortion. OCR tuned for flatbed scanner input fails on this image class at rates that make manual review unavoidable, which eliminates the operational value these pipelines were supposed to provide.
Deep learning models trained on specific issuing country variants get more accurate on documents they've seen. They still can't validate checksums, reconcile VIZ against MRZ, or route Cyrillic surnames to the right recognition model. There are over 190 ICAO-member countries, each with different VIZ layouts, typefaces, and biometric page designs. A model trained on EU biometric passports degrades when Central African or Southeast Asian variants start appearing at volume. Each time, the fix is the same: more data collection, more labeling, more retraining. None of it touches the checksum-unaware, script-agnostic extraction underneath. Agentic OCR doesn't need a new training set for each issuing country. It handles these as structural requirements through layout understanding and model routing.
Why Agentic Orchestration Changes What Passport OCR Can Actually Guarantee
Standard OCR applies one pipeline uniformly to the entire passport image. The failure modes above are structural consequences of treating a document with functionally distinct zones as a flat image to be processed identically.
Agentic OCR changes the processing model. Layout-aware computer vision segments the passport image into zones before extraction begins: the MRZ strip, the VIZ text fields, the photo region, the hologram overlay area, stamp regions if present. Each zone is routed to the model best suited for what it contains.
The MRZ goes to a parser that validates checksums, not just extracting characters but running the weighted modulo-10 validation on each check digit and verifying the composite checksum. Failed checksums surface immediately instead of propagating incorrect data downstream. The VIZ gets processed with script detection active, routing Arabic, CJK, and Cyrillic name data fields to appropriate models. Hologram-affected regions are processed with awareness of specular reflection rather than treating glare as character data.
Self-correction loops compare VIZ fields against their MRZ counterparts: name, date of birth, passport number, expiry date. Discrepancies are flagged with field-level confidence scores before structured data reaches downstream identity verification processes. This happens during the extraction pass itself, not in a separate audit step.
LlamaParse uses this agentic document processing approach: zone-aware layout detection, model selection per document element, checksum validation, and verifiable output with per-field confidence scores. Having processed over a billion documents across 90+ file formats without requiring custom training per document type, it handles passport format variants from different issuing countries through layout understanding and model routing rather than a new labeled dataset for each one.
Here's what a passport extraction call looks like:
html
from llama_parse import LlamaParse
parser = LlamaParse(result_type="json")
result = parser.load_data("passport_scan.jpg")The extraction surfaces field-level confidence scores rather than a raw character string:
html
{
"document_type": "PASSPORT",
"issuing_country": "USA",
"last_name": "SMITH",
"given_names": "JOHN WILLIAM",
"nationality": "USA",
"date_of_birth": "1980-01-14",
"passport_number": "123456789",
"expiry_date": "2031-01-23",
"mrz_line_1": "P<USASMITH<<JOHN<WILLIAM<<<<<<<<<<<<<<<<<<<<",
"mrz_line_2": "1234567895USA8001014M3101235<<<<<<<<<<<<<<<6",
"mrz_checksum_valid": true,
"viz_mrz_match": true,
"confidence_scores": {
"last_name": 0.99,
"given_names": 0.97,
"passport_number": 0.99,
"date_of_birth": 0.98,
"expiry_date": 0.99
}
}This is what structured passport data extraction looks like in practice, not a flat MRZ string with no verification layer attached.
Where Passport OCR Accuracy Determines Operational Outcomes
Passport OCR failure doesn't look the same in every deployment context. Three environments illustrate how different the stakes are.
Travel & Hospitality: Real-Time Capture, No Review Queue
Hotel check-in and airline boarding are the most unforgiving environments for passport OCR. The capture happens on a consumer smartphone under variable lighting. Extraction has to complete in under two seconds. There is no manual review queue. If the pipeline fails, the agent types the data by hand, eliminating the operational value the system was supposed to deliver.
Travel documentation errors are immediately visible. A denied boarding because OCR misread an expiry date. A check-in line stalled because a Cyrillic surname didn't extract cleanly from a worn document. The pipeline has to handle worn documents, off-angle captures, and non-Latin names at the extraction stage. Routing failures to a fallback queue that doesn't exist in a real-time boarding flow isn't a solution.
Remote Onboarding & Digital Identity Platforms
Financial account opening, insurance enrollment, and government benefit registration increasingly accept passport as the primary identity document, submitted via smartphone during a digital onboarding flow. Passport OCR API integration connects directly to AML screening databases and compliance audit trails.
Extraction errors at this stage propagate through every downstream check. As covered in OCR for KYC, a transposed passport number in the KYC record generates a false AML watchlist hit. A misread expiry date passes an expired document as valid. Field-level confidence scores matter here. Compliance systems need to distinguish high-confidence extractions from fields that warrant human review. Returning all extracted fields as equally trustworthy output is not an adequate interface when extracting data feeds directly into compliance-critical records.
Government Services & High-Volume Immigration
Border control and immigration processing are the highest-volume context for passport document processing: hundreds of thousands of documents per day at major airports, processed in sub-second windows. At this scale, MRZ checksum validation and VIZ-MRZ discrepancy detection are the primary mechanisms for document fraud detection at the extraction layer.
A system that skips checksum validation at this volume is performing fast transcription, not identity verification. A 0.1% error rate on one million documents per day means 1,000 potentially fraudulent or corrupted documents passing through without a flag. Data processing errors carry consequences that go well past operational inefficiency: a wrong nationality, a transposed document number, an expired document passed as valid.
Passport OCR Without MRZ Validation Is Just Character Recognition
Most passport OCR failures in production come from architectures built as if passport data is ordinary printed text. They extract characters without validating checksums, without cross-checking VIZ fields against MRZ encodings, without routing non-Latin scripts to appropriate models, and without accounting for hologram interference on mobile captures.
In any real deployment serving international travelers, digital onboarding flows, or government services, these conditions are the baseline, not the edge case. The gap between demo-condition accuracy and production accuracy is predictable and structural. It widens exactly where it matters most: on the documents that arrive worn, photographed sideways, or that have a surname that isn't in the Latin alphabet.
For teams building identity verification or onboarding workflows that depend on passport extraction, LlamaParse is worth benchmarking against your actual document set, not the clean scans from a vendor's controlled demo. The MRZ validation layer, VIZ-MRZ cross-check, and script-aware routing are what separate reliable production extraction from a system that performs well in testing and breaks on the first worn passport with a Cyrillic surname.