

Insurance claims are rarely straightforward. A single claim can involve multiple documents arriving from different sources, each carrying partial information that must be interpreted collectively. A medical claim, for instance, may include a hospital invoice, discharge summary, prescription records, and supporting documents submitted by the policyholder. None of these documents, on their own, are sufficient to make a decision. The value lies in how they connect.
This is where traditional document processing systems begin to struggle.
While optical character recognition can convert scanned documents into text, insurance workflows require far more than readable output. They require structured, validated, and cross-referenced data that can support underwriting decisions, compliance checks, and fraud detection. Extracting numbers without preserving their context introduces risk rather than reducing it.
OCR for insurance documents must therefore operate as part of a broader document understanding system, one that reconstructs structure, preserves relationships between fields, and enables decision-ready data.
Why Insurance Document Processing Breaks in Practice
Insurance documents are inherently variable. A single claim file may contain documents generated by hospitals, vendors, law enforcement agencies, and customers. Each document type follows its own layout conventions, formatting rules, and content structures.
A hospital invoice may contain structured tables with line items and totals. A discharge summary may include narrative descriptions of treatment. A prescription may contain handwritten annotations. Even within the same category, formats can differ significantly depending on the issuing entity.
This variability creates a fundamental limitation for traditional OCR systems.
Character recognition alone does not preserve relationships between values. A system may correctly extract a total amount from an invoice but fail to associate it with the corresponding line items. Similarly, dates, identifiers, and descriptions may be extracted accurately but lose their meaning when processed independently.
Insurance workflows also depend heavily on cross-document validation. A claim amount must align with invoice totals, treatments must match prescriptions, and policy details must remain consistent across all documents. Without structured parsing and validation logic, these relationships cannot be enforced reliably.
As document volume increases, manual review becomes a bottleneck, and template-based systems become fragile. This is the operational reality that drives the need for intelligent document processing.Benchmark accuracy alone often fails to reflect real-world document complexity, especially in industries such as insurance where layouts, image quality, and cross-document relationships vary significantly. OLMOCR Bench Review: Insights and Pitfalls on an OCR Benchmark explores why benchmark performance does not always translate into production reliability.
From OCR Output to Structured Insurance Data
To support claims processing, document extraction must move beyond text recognition and toward structured data reconstruction.
Modern systems combine machine learning, computer vision, and layout-aware parsing to interpret documents at multiple levels. Text detection identifies regions of interest, while layout analysis determines how those regions are organized into sections such as headers, tables, and key-value fields. Structural parsing then reconstructs these elements into schema-aligned outputs.
For example, in a hospital invoice, each charge must remain associated with its description, quantity, and billing category. Table reconstruction is particularly important in insurance invoices where billing rows, quantities, and totals must preserve their relationships during extraction. OCR for Tables: How to Extract Structured Data from Documents explains how layout-aware parsing preserves table integrity in complex documents. Extracting these values independently leads to fragmented data that cannot be validated or used in downstream systems.
Validation is integrated into this process rather than applied afterward. Extracted values are checked against business rules, policy coverage, and supporting documents. Confidence scoring determines whether the data can be processed automatically or requires human review. This ensures that automation improves efficiency without compromising accuracy.
Insurance Document Automation Workflow
A production-ready OCR workflow for insurance documents must operate as a coordinated system rather than a sequence of isolated steps.
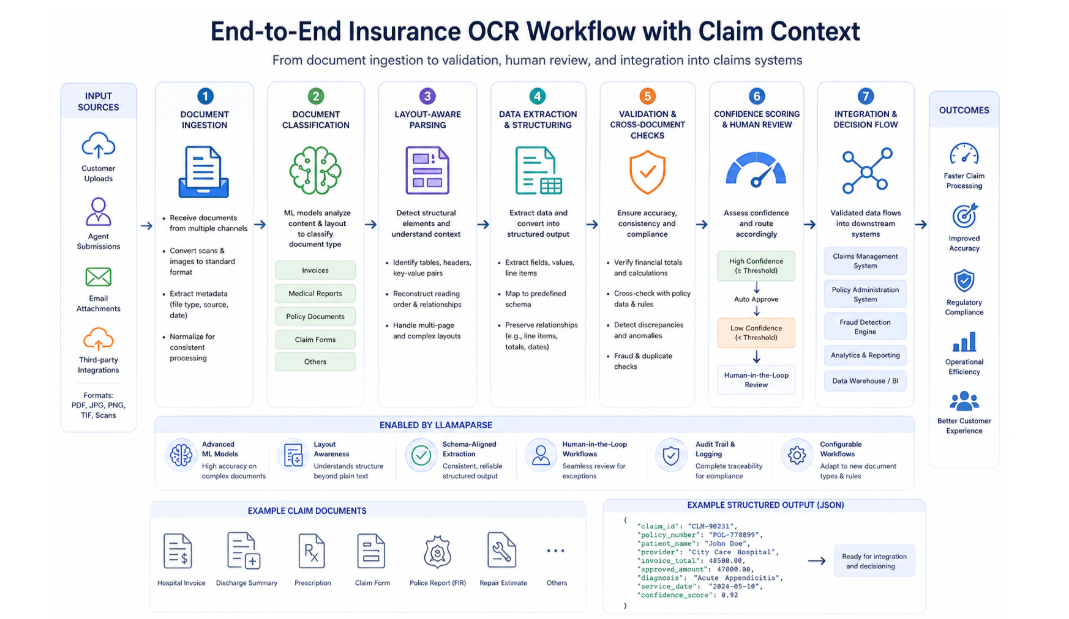
Documents enter the system through multiple channels, including customer uploads, agent submissions, and third-party integrations. These inputs are normalized into a consistent format to ensure downstream processing operates reliably.
Once ingested, documents are classified into categories such as invoices, medical reports, and policy documents. This classification step determines which extraction logic and validation rules will be applied.
Layout-aware parsing then identifies structural components within each document. Tables, headers, and key-value fields are reconstructed into structured representations. This ensures that extracted data maintains relationships between fields rather than being treated as flat text.
Following extraction, validation workflows enforce consistency across documents. Financial values are verified against totals, policy data is cross-referenced, and discrepancies are identified. Confidence scoring determines whether the extracted data can proceed automatically or requires human review.
Finally, validated data is integrated into claims processing systems, enabling automated decision-making, compliance reporting, and analytics workflows.
Real-World Challenges in Insurance Document Automation
Even with advancements in machine learning and document understanding, insurance document automation continues to face several structural and operational challenges that must be addressed at the system design level rather than treated as edge cases.
Document Variability Across Insurance Providers
Document variability remains one of the most persistent issues. Insurance workflows involve documents generated by multiple external entities, including hospitals, repair vendors, and regulatory bodies, each with its own formatting conventions.
These formats evolve over time without notice, introducing new layouts, additional fields, or modified structures. Systems that rely on fixed templates or rigid parsing rules struggle to keep up with this variability, resulting in frequent failures or increased maintenance overhead.
Production-grade systems must therefore incorporate layout-aware models and adaptive parsing strategies that can generalize across unseen formats without requiring constant reconfiguration.
Benchmark accuracy alone often fails to reflect real-world document complexity, especially in industries such as insurance where layouts, image quality, and cross-document relationships vary significantly. OLMOCR Bench Review: Insights and Pitfalls on an OCR Benchmark explores why benchmark performance does not always translate into production reliability.
Low-Quality Scans and Handwritten Documents
Image quality introduces another layer of complexity that directly impacts extraction reliability.
Documents are often submitted as scanned copies, mobile-captured images, or compressed PDFs, all of which may include skewed alignment, motion blur, shadows, or low resolution. Handwritten annotations further complicate extraction, especially when mixed with printed text.
While preprocessing techniques such as deskewing, noise reduction, and contrast normalization improve baseline performance, they cannot fully eliminate ambiguity. As a result, systems must be designed to handle imperfect inputs and incorporate confidence-based validation to manage uncertainty effectively.
Cross-Document Validation Complexity
Cross-document validation is central to insurance workflows but introduces significant complexity in automation.
A single claim requires consistency across multiple documents, where financial values, treatment details, and policy information must align. Invoice totals must reconcile with line items, prescribed treatments must match billed services, and claim amounts must remain within policy limits.
These relationships cannot be verified through isolated extraction. Instead, systems must implement coordinated validation logic that compares structured outputs across documents and applies domain-specific rules to detect discrepancies.
Fraud Detection and Anomaly Identification
Fraud detection further amplifies this challenge.
Inconsistent data across documents may indicate errors, but it may also signal intentional manipulation. Automated systems must therefore identify anomalies such as duplicated invoices, inflated billing, or mismatched treatment records while maintaining a low false-positive rate.
This requires combining extraction accuracy with contextual validation and anomaly detection mechanisms.
Regulatory Compliance and Auditability
Regulatory and compliance requirements impose additional constraints on system design.
Insurance processes demand full traceability, meaning every extracted value, validation step, and decision must be auditable. Systems must maintain detailed logs, including confidence scores, validation outcomes, and any human corrections applied during review.
This ensures that decisions can be explained during audits and regulatory checks, which is critical in highly regulated environments.
Why These Challenges Require System-Level Design
These challenges highlight that effective OCR for insurance documents is not solely a recognition problem.
It is a system-level problem that requires integrating extraction, validation, adaptability, and governance into a unified workflow capable of operating reliably under real-world conditions.
OCR for Insurance Documents with LlamaParse
LlamaParse approaches insurance document processing as a structured workflow that combines document understanding, schema-aligned extraction, and validation orchestration within a unified system. Rather than treating OCR as a standalone text recognition task, LlamaParse preserves document structure, contextual relationships, and cross-document consistency requirements that are essential in insurance operations.
As insurance claims workflows become increasingly dependent on automation, extraction systems must operate reliably across invoices, discharge summaries, prescriptions, policy documents, and supporting records without losing structural relationships during processing. This broader transition reflects the evolution from traditional OCR systems toward intelligent document workflows capable of reasoning across multiple document types and validation stages. Introducing Agentic Document Workflows provides additional context on how modern document systems are evolving beyond isolated text extraction pipelines.
Layout-Aware Parsing and Structured Extraction
Within LlamaParse, document analysis begins with layout-aware parsing that identifies structural components such as tables, multi-column sections, headers, nested fields, and key-value relationships. This ensures that extraction logic follows document structure rather than relying exclusively on character recognition.
In insurance workflows, preserving these structural relationships is critical because financial totals, treatment descriptions, diagnosis information, and policy metadata must remain connected to their surrounding context to support downstream validation. A hospital invoice, for example, cannot be processed reliably if billing categories, quantities, and totals are extracted independently without maintaining relationships between fields.
Structured parsing operates on top of this layout analysis to generate schema-aligned outputs that can integrate directly into claims systems. Instead of producing flat text responses, LlamaParse reconstructs documents into structured representations aligned with operational requirements. Insurance workflows commonly require extraction of claim identifiers, patient information, invoice line items, treatment summaries, policy details, and supporting metadata in formats that downstream systems can process without additional transformation logic.
Table reconstruction also plays an important role in insurance extraction workflows where billing rows, quantities, and totals must preserve their hierarchical relationships during processing. OCR for Tables: How to Extract Structured Data from Documents explains how layout-aware parsing improves extraction reliability across complex tabular documents.
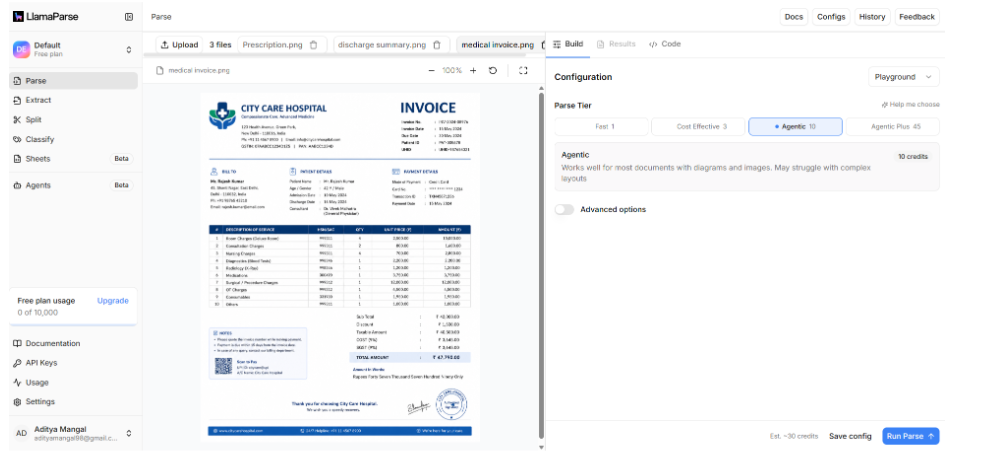
To understand how this workflow operates in practice, consider a medical reimbursement claim submitted by a policyholder.
The claim includes:
- A scanned hospital invoice
- A multi-page discharge summary
- Prescription documents with handwritten annotations
When processed using LlamaParse, these documents are not treated as independent inputs. Instead, they are interpreted within a unified claim context.
The invoice is parsed to extract structured financial data, including line items, totals, and billing categories. The discharge summary is analyzed to extract diagnosis and treatment information. Prescription documents are processed to identify medications and correlate them with billed services. Similar extraction challenges appear in receipt processing workflows where inconsistent layouts, fragmented fields, and variable formatting can break traditional OCR systems. Agentic OCR for Receipts explores how intelligent parsing improves reliability across unstructured financial documents.
The resulting output is a structured representation of the claim:
html
{
"claim_id": "CLM-202405-98765",
"patient_name": "Mr. Rajesh Kumar",
"patient_id": "PAT-005678",
"hospital": "City Care Hospital",
"admission_date": "2024-05-10",
"discharge_date": "2024-05-14",
"diagnosis": "Acute Appendicitis",
"invoice_details": {
"invoice_id": "INV-2024-08976",
"invoice_date": "2024-05-15",
"total_amount": 47790.00,
"sub_total": 42000.00,
"tax_amount": 7290.00
},
"line_items": [
{
"description": "Room Charges (Deluxe Room)",
"amount": 10000.00
},
{
"description": "Consultation Charges",
"amount": 1600.00
},
{
"description": "Surgical / Procedure Charges",
"amount": 12000.00
},
{
"description": "Medications",
"amount": 3750.00
}
],
"prescription_summary": [
"Pantoprazole 40 mg",
"Cefixime 200 mg",
"Metronidazole 400 mg",
"Paracetamol 650 mg",
"Ondansetron syrup",
"Probiotic capsules",
"Calcium + Vitamin D3"
],
"validated_amount": 46290.00,
"discrepancies": [
"OT Charges billed but not explicitly supported in prescription",
"Consumables not listed in prescription or discharge summary"
],
"cross_document_checks": {
"diagnosis_match": true,
"treatment_match": true,
"invoice_vs_prescription_consistency": false
},
"confidence_score": 0.91
}This structured representation allows downstream systems to validate claims automatically, identify inconsistencies across supporting documents, and selectively route exceptions for human review. Because relationships between extracted fields remain preserved, validation systems can reason across documents rather than evaluating isolated values independently.
Validation and Confidence-Based Workflows
Validation is integrated directly into the extraction workflow rather than treated as a downstream correction step. Extracted values can be reconciled against business rules, policy constraints, and cross-document relationships during processing itself.
For example, invoice totals can be validated against line items, treatment details can be compared with prescriptions, and claim amounts can be checked against policy coverage before the data enters downstream approval systems. These validation layers reduce error propagation and improve operational reliability across high-volume claims environments where inconsistencies can introduce compliance and financial risks.
Cross-document validation is particularly important in insurance workflows because a single claim often depends on consistency across multiple independent records. Extraction alone does not guarantee correctness. Systems must verify whether diagnoses align with treatments, whether billed procedures match prescriptions, and whether financial values remain consistent across invoices and supporting documentation.
Confidence scoring further strengthens workflow governance by assigning reliability metrics to extracted fields based on contextual signals and model predictions. High-confidence data can proceed through automated workflows without intervention, while lower-confidence outputs can trigger human-in-the-loop review processes. This selective review model allows organizations to scale automation without sacrificing operational oversight for ambiguous or high-risk cases.
Configuration-Driven Integration and Workflow Orchestration
LlamaParse also supports configuration-driven workflow design, which reduces the operational overhead associated with traditional OCR implementations. Conventional systems frequently depend on rigid templates and manually engineered parsing rules that become difficult to maintain as document formats evolve. In contrast, LlamaParse allows organizations to configure extraction logic, schema mappings, validation rules, and workflow behavior according to operational requirements without rebuilding pipelines for every document variation.
This adaptability is important in insurance environments where providers, hospitals, and regulatory entities frequently modify document layouts, introduce new fields, or change formatting structures. Systems that rely heavily on fixed templates often require continuous maintenance, whereas configurable parsing workflows can generalize more effectively across evolving document ecosystems.
Because LlamaParse operates within a broader document processing ecosystem, extracted insurance data can integrate directly into claims management systems, fraud detection platforms, analytics environments, and compliance workflows. This reduces fragmentation between extraction logic and operational systems while enabling organizations to transition from manual document handling toward scalable, production-grade automation.
Many of the same validation and reconciliation requirements also appear in financial automation workflows such as invoice approvals and accounts payable operations. OCR for Accounts Payable: Benefits, Challenges, and Best Practices explores how structured extraction and validation workflows improve operational reliability in high-volume financial processing environments.
Best Practices for Implementing OCR in Insurance Workflows
Successful implementation of OCR for insurance documents requires more than selecting a capable extraction tool. Insurance workflows operate in environments where document variability, validation requirements, compliance obligations, and operational risk must all be managed simultaneously. Production-grade systems therefore need to combine structured parsing, validation orchestration, governance controls, and workflow adaptability within a unified processing architecture.
Define Structured Schemas Before Deployment
A foundational requirement for insurance automation is establishing clearly defined document schemas before deployment. Insurance workflows depend on consistent extraction structures across invoices, medical reports, discharge summaries, prescriptions, and policy documents. Without predefined schemas, extracted values become difficult to validate, reconcile, and integrate into downstream claims systems.
For example, invoice extraction workflows must preserve relationships between billing categories, quantities, financial totals, and supporting metadata in formats that downstream systems can process reliably. Structured schemas also improve interoperability between claims platforms, fraud detection systems, analytics pipelines, and compliance workflows.
Embed Validation Logic into the Workflow
Validation should operate as an integrated part of the extraction pipeline rather than a downstream correction step. Insurance decisions rely heavily on cross-document consistency, which means extracted values must be verified against multiple independent records before approval workflows proceed.
Claim amounts should reconcile with invoice totals, treatment descriptions should align with prescriptions and discharge summaries, and policy information must remain consistent across all supporting documentation. Extraction alone does not guarantee correctness. Systems must apply coordinated validation logic capable of comparing structured outputs across multiple documents while identifying discrepancies that require additional review.
Many of the same validation and reconciliation requirements also appear in financial automation workflows such as invoice approvals and accounts payable operations. OCR for Accounts Payable: Benefits, Challenges, and Best Practices explores how structured extraction workflows improve operational reliability across high-volume financial processing environments.
Design for Uncertainty and Human Review
No OCR system operates with perfect accuracy across every document type and input condition. Insurance workflows frequently involve handwritten annotations, low-quality scans, compressed PDFs, mobile-captured images, and evolving layouts that introduce ambiguity into extraction pipelines.
Confidence scoring should therefore operate at the field level to evaluate extraction reliability and determine whether outputs can proceed automatically or require human review. High-confidence fields can move through automated workflows, while low-confidence values should trigger exception handling and manual verification processes.
Human-in-the-loop workflows remain particularly important in insurance environments where incorrect approvals, missed inconsistencies, or unresolved ambiguities can introduce compliance, financial, and operational risk. Selective human review enables organizations to scale automation while maintaining governance controls over complex or uncertain cases.
Prioritize Layout-Aware Parsing and Preprocessing
Preprocessing and layout-aware parsing should be treated as core architectural components rather than optional enhancements. Insurance documents are frequently submitted with skewed alignment, inconsistent formatting, motion blur, shadows, compression artifacts, and handwritten notes that reduce extraction reliability.
Preprocessing techniques such as image normalization, orientation correction, contrast enhancement, and noise reduction improve baseline OCR performance before structured parsing begins. However, preprocessing alone is insufficient without layout-aware extraction capable of preserving relationships between tables, key-value pairs, headers, and nested document sections.
This becomes particularly important in insurance invoices where line items, billing categories, and totals must remain structurally connected during extraction. Misaligned tables or fragmented field relationships can introduce validation failures and downstream processing errors even when character recognition itself appears accurate.
Build for Evolving Document Ecosystems
Insurance document ecosystems continuously evolve as hospitals, providers, repair vendors, and regulatory entities introduce new layouts, modified templates, and additional fields. Systems that rely heavily on rigid extraction templates often become operationally expensive to maintain because every structural change requires additional rule engineering and reconfiguration.
Production-grade OCR systems should instead combine machine learning–based parsing with configurable extraction logic that can generalize across unseen document variations. This adaptability reduces maintenance overhead while improving long-term operational scalability across changing document environments.
Maintain Governance and Auditability
Insurance workflows operate under significant regulatory and compliance obligations that require full traceability across extraction and decision-making pipelines. Every extracted value, validation outcome, confidence score, and human correction must remain auditable throughout the workflow lifecycle.
Systems should maintain detailed operational logs that capture extraction decisions, validation checks, exception handling actions, and manual review outcomes. This level of traceability supports regulatory audits, improves operational visibility, and enables organizations to evaluate extraction performance over time.
Governance requirements also extend beyond compliance. Structured audit trails provide operational teams with the visibility needed to identify recurring extraction failures, refine validation logic, and continuously improve workflow reliability across production environments.
Conclusion
OCR for insurance documents transforms document-heavy workflows into structured, reliable systems that support faster and more accurate claims processing. By combining machine learning, layout-aware parsing, and validation workflows, organizations can extract meaningful data from complex documents while maintaining compliance, auditability, and operational control. This shift reduces manual intervention, improves consistency across claims, and enables insurers to process higher volumes without compromising accuracy.
However, sustainable automation requires more than text extraction. It depends on the ability to preserve relationships between data points, validate information across multiple documents, and handle variability in real-world inputs. Systems that incorporate structured parsing, cross-document validation, and confidence-based decisioning are better equipped to support production environments where accuracy and traceability are critical.
LlamaParse enables this transformation by providing a platform that integrates document understanding, structured parsing, and validation orchestration within a unified workflow. Rather than requiring teams to build pipelines from scratch, it allows organizations to configure extraction logic, validation rules, and schema mappings based on their operational needs. This configuration-driven approach reduces engineering overhead while improving adaptability to new document formats and evolving requirements.
As insurance workflows continue to grow in complexity, the ability to process documents as structured, validated data becomes a foundational capability. LlamaParse supports this transition by enabling organizations to move from manual, document-centric processes to scalable, automation-driven systems that are both efficient and reliable.